Systems / Performance Project
Lock-Free Ring Buffer Benchmark
A lock-free single-producer, single-consumer ring buffer in C++ with a comprehensive benchmark suite for analyzing contention strategies, queueing behavior, and latency tradeoffs.
Key Features
- Lock-free SPSC implementation using atomics
- Four wait strategies for contention analysis
- High-resolution latency metrics
- CPU affinity support for consistent scheduling
- Capacity sweep for backpressure effects
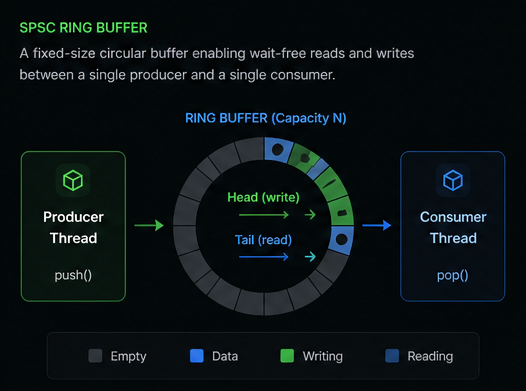
Architecture
- Fixed-size circular buffer backed by contiguous storage
- Separate producer and consumer indices for SPSC ownership
- Acquire and release memory ordering protects data visibility
- Cache-line alignment reduces false sharing between hot atomics
- Benchmark harness is separated from queue implementation logic
How It Works
- Producer writes an item into the current tail slot
- Producer release-stores the new tail so the consumer can see the write
- Consumer acquire-loads the tail before reading from the buffer
- Consumer reads from the current head slot and advances the head
- Failed pushes mean the buffer is full, while failed pops mean it is empty
Benchmark Output
=== Throughput: Wait Strategy Comparison === Benchmark msgs/s(M) fail_push fail_pop ----------------------------------------------------------------- Spin 16.41 19 1921676 Yield 27.38 204 32985 SpinThenYield 24.55 1499 551720 ExponentialBackoff 20.21 2645 327247 === Latency: Wait Strategy Comparison === Benchmark avg(ns) p50 p95 p99 max ------------------------------------------------------------------------------- Spin 93846.92 92441.60 106425.20 115458.20 134788.60 Yield 78351.52 77100.00 88166.40 96366.60 139583.20 SpinThenYield 92853.83 92175.00 100424.80 110566.40 128641.80 ExponentialBackoff 98410.68 95683.60 120675.00 131950.00 174291.60 === Throughput: Capacity Sweep === Capacity msgs/s(M) fail_push fail_pop ----------------------------------------------------------------- 64 16.54 24904 1261885 256 17.12 18212 813192 1024 22.49 1261 694032 8192 27.24 3653 207194 === Latency: Capacity Sweep === Capacity avg(ns) p50 p95 p99 max ------------------------------------------------------------------------------- 64 6313.10 5966.80 7533.20 8774.80 75908.40 256 23229.12 25991.20 25991.80 36441.60 40866.60 1024 92822.79 92116.80 99266.60 116816.80 148625.00 8192 765703.84 741950.00 934133.40 1067608.60 1311267.00
Highlights
- Lock-free SPSC queue built with C++20 atomics
- Benchmarks compare Spin, Yield, SpinThenYield, and ExponentialBackoff strategies
- Measures throughput, failed push/pop attempts, and tail latency percentiles
- Uses CPU affinity to reduce scheduling noise during benchmark runs
- Explores how queue capacity affects throughput and tail latency
- Demonstrates acquire/release synchronization in a real producer-consumer system
- Separates benchmark logic, wait strategies, formatting, and queue implementation
Performance Analysis
- Compare wait strategies under contention
- Measure throughput and tail latency
- Understand CPU scheduling impact
- Identify tradeoffs between latency and throughput
What I Learned
- Yielding improves throughput under contention
- Larger buffers increase latency due to queueing
- Backoff strategies are not always beneficial
- Thread affinity exposes true system behavior
Tech Stack
- C++20 (atomics, threads, chrono)
- CMake
- Linux (sched_setaffinity)
- Custom benchmark harness